Elasticsearch深入搜索,搜索的相关性Relevance和相关性算分
什么是相关性Relevance
搜索相关性的算分,描述了一个文档和查询语句的匹配程度。ES会对每个匹配查询条件的结果进行算分_score。
打分的本质是排序,需要把最符合用户需求的文档排在前面
ES5之前默认的相关性算分采用算法TF-IDF,现在采用BM 25
词频 TF(Term Frequency)
检索词在一篇文档中出现的频率,检索词出现的次数/文档的总次数
度量一条查询和结果文档相关性的简单方法:简单将搜索中的每一个词的TF进行相加
Stop Word
“的”等词在文档中出现了很多次,但对贡献相关度几乎没有用处,不应该考虑他们的TF
逆文档频率 IDF(Inverse Document Frequency)
log(全部文档数/检索词出现过的文档总数)
DF(Document Frequency): 检索词在所有文档中出现的频率
TF-IDF本质上就是将TF求和变成了加权求和
概念
IF-IDF被公认为是信息检索领域最重要的发明,除了在信息检索,在文献分类和其他相关领域有着非常广泛的应用。
IDF的概念,最早是剑桥大学的“斯巴克·琼斯”提出的,1972年-“关键词特殊性的统计解释和它在文献检索中的应用”。但是没有从理论上解释IDF应该是用log(全部文档数/检索词出现过的文档的总数。1970、1980年代萨尔顿和罗宾逊,进行了进一步的证明和研究,并用香农信息论做了证明。现代搜索引擎,TF-IDF进行了大量细微的优化。
Lucene中的TF-IDF评分公式
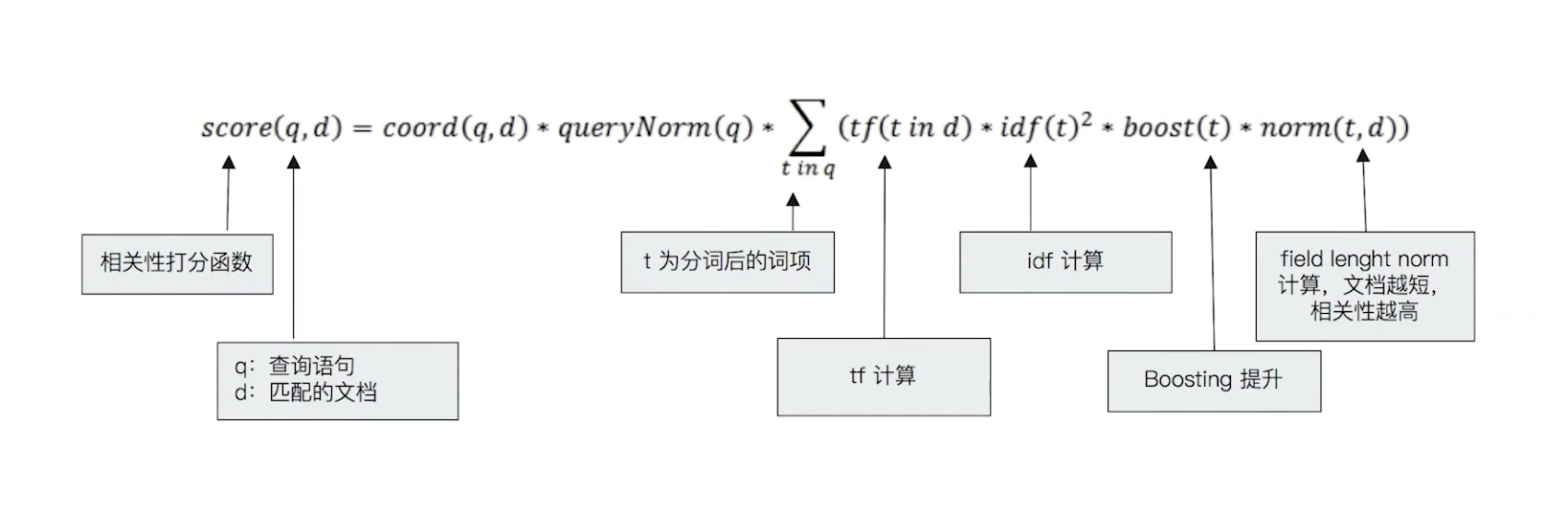
BM25
从ES5开始,默认算法改为BM25。和经典的TF-IDF相比,当TF无限增加时,BM25算分会趋于一个数值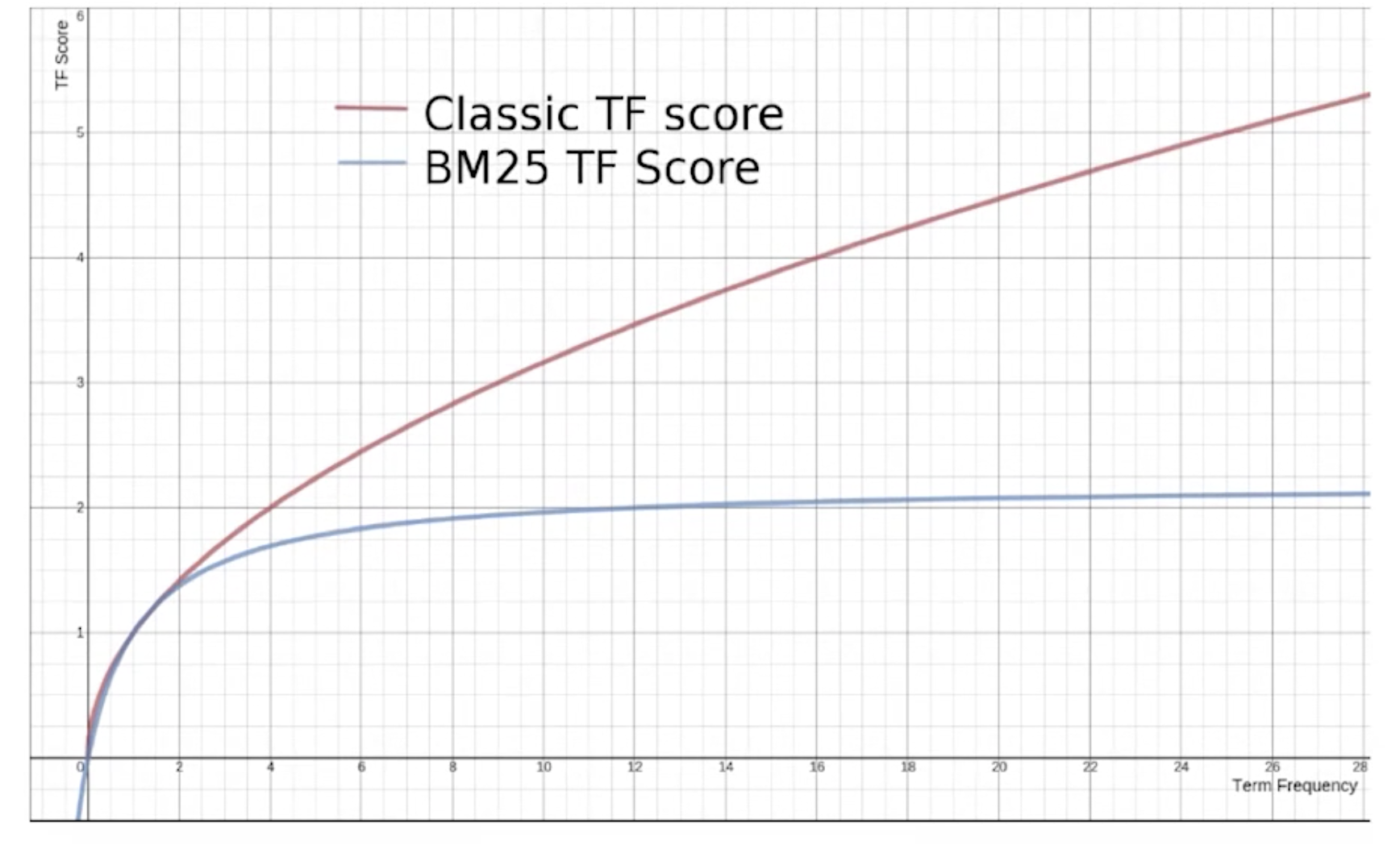
定制Similarity
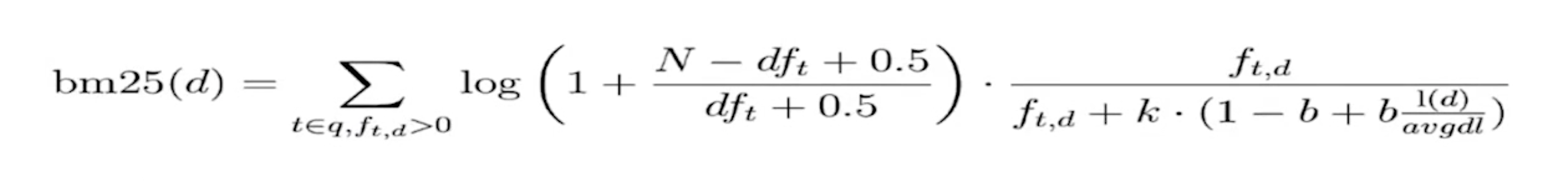
- K默认值为1.2,数值越小,饱和度越高。
- b默认值是0.75(范围0-1),0表示禁止Normalization
示例
1 | PUT /my_index |
通过Explain API查看TF-IDF
示例
准备数据1
2
3
4
5
6
7
8
9PUT testscore/_bulk
{ "index": { "_id": 1 }}
{ "content":"we use Elasticsearch to power the search" }
{ "index": { "_id": 2 }}
{ "content":"we like elasticsearch" }
{ "index": { "_id": 3 }}
{ "content":"The scoring of documents is caculated by the scoring formula" }
{ "index": { "_id": 4 }}
{ "content":"you know, for search" }
设置explain为true查看执行计划,description中有显示算分逻辑1
2
3
4
5
6
7
8
9
10
11
12POST /testscore/_search
{
"explain": true,
"query": {
"match": {
//"content":"you"
"content": "elasticsearch"
//"content":"the"
//"content": "the elasticsearch"
}
}
}
Boosting Relevace
Boosting是控制相关度的一种手段。可以在索引、字段或查询子条件设置。
参数boost的含义
- boost > 1 , 打分的相关度相对性提升
- 0 < boost < 1, 打分的权重相对性降低
- boost < 1, 贡献负分
1 | POST testscore/_search |

