Elasticsearch深入搜索,Term查询和全文查询很容易混淆,这里记录下两者的区别
基于Term的查询
- Term的重要性: Term是表达语义的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理Term
特点
- Term Level Query:Term Query/Range Query/Exists Query/Prefix Query/Wildcard Query
- 在ES中,Term查询对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分
- 可以通过Constant Score将查询转换成一个Filtering避免算分,并利用缓存提高性能
示例
初始化数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
DELETE products
PUT products
{
"settings": {
"number_of_shards": 1
}
}
POST /products/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" }
{ "index": { "_id": 2 }}
{ "productID" : "KDKE-B-9947-#kL5","desc":"iPad" }
{ "index": { "_id": 3 }}
{ "productID" : "JODL-X-1937-#pV7","desc":"MBP" }
GET /products
ES对Term搜索的值不做任何处理,而ES在做数据的索引操作的时候,会对Text的内容做默认的分词处理,
由于标准分词器会对单词进行小写转换,所以需要用小写来进行Term查询。
可以设置搜索字段的keyword属性进行原文的查询1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47POST /products/_search
{
"query": {
"term": {
"desc": {
//"value": "iPhone"
"value":"iphone"
}
}
}
}
POST /products/_search
{
"query": {
"term": {
"desc.keyword": {
//"value": "iPhone"
//"value":"iphone"
}
}
}
}
POST /products/_search
{
"query": {
"term": {
"productID": {
//"value": "XHDK-A-1293-#fJ3"
"value": "xhdk"
}
}
}
}
POST /products/_search
{
//"explain": true,
"query": {
"term": {
"productID.keyword": {
"value": "XHDK-A-1293-#fJ3"
}
}
}
}
复合查询 Constant Score转为Filter
搜索时会返回_score字段,是ES的一个算分结果。但是如果我们想要跳过这个步骤。
- 将Query转成Filter,忽略TF-IDF计算,避免相关性算分的开销
- Filter可以有效利用缓存
1 | POST /products/_search |
总结
Term查询不会进行分词,如果希望完全匹配,可以利用ES的多字段属性,会默认为字段添加keyword字段进行严格匹配搜索。
基于全文的查询
- Match Query/Match Phrase Query/Query String Query
特点
- 索引和搜索时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表
- 查询的时候,先会对输入的查询进行分词,然后每个词项逐个进行底层的查询,最终将结果进行合并。并为每个文档生成一个算分。
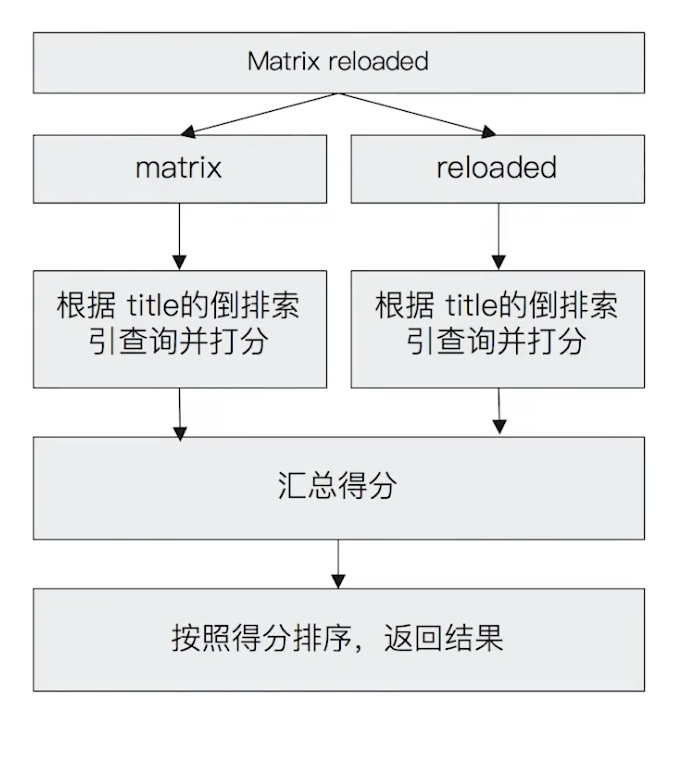
例如”Matrux reloaded”,会查到包括”Matrix”或”reload”的所有结果
Match Query查询过程
两者比较和总结
- 基于词项的查找(不会做分词处理) vs 基于全文的查找(会做分词处理)
- 通过Mapping控制字段的分词,Keyword类型数据在写入的时候不会做分词的处理
- 通过参数控制查询的Precision&Recall
- 复合查询 Constant Score查询
- 即便是对Keyword进行Term查询,同样会进行算分
- 可以将查询转为Filtering,取消相关性算分环节以提升性能

