分词相关概念的记录
Analysis与Analyzer
Analysis
文本分析是把全文本转换为一系列的单词(term/token)的过程,也叫分词
通过Analyzer实现,可使用Elasticsearch内置的分析器,或者按需定制化分析器
除了在数据写入时转换词条,匹配Query语句时也需要用相同的分析器对查询语句进行分析
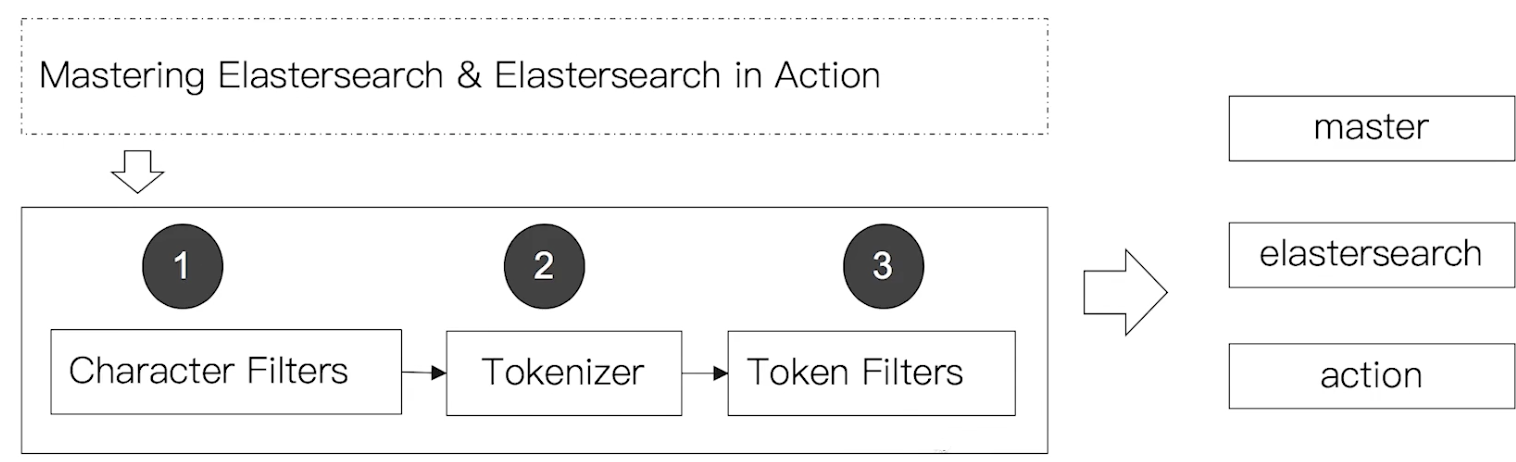
1 | Elasticsearch Server --分词--> elasticsearch、server |
Analyzer
分词器是专门处理分词的组件,Analyzer由三部分组成
- Character Filters 针对原始文本处理,例如去除html
- Tokenizer 按照规则切分为单词
- Token Filter 将切分的单词进行加工,小写,删除Stopwords,增加同义词
Elasticsearch内置分词器
- Standard Analyzer 默认分词器,按词切分,小写处理
- Simple Analyzer 按照非字母切分(符号被过滤),小写处理
- Stop Analyzer 小写处理,停用词过滤(the, a, is)
- Whitespace Analyzer 按照空格切分,不转小写
- Keyword Analyzer 不分词,直接将输入当作输出
- Patter Analyzer 正则表达式,默认\W+(非字符分割)
- Language 提供了30多种常见语言的分词器
- Customer Analyzer 自定义分词器
查看不同的analyzer的效果
1 | # standard |
_analyzer API
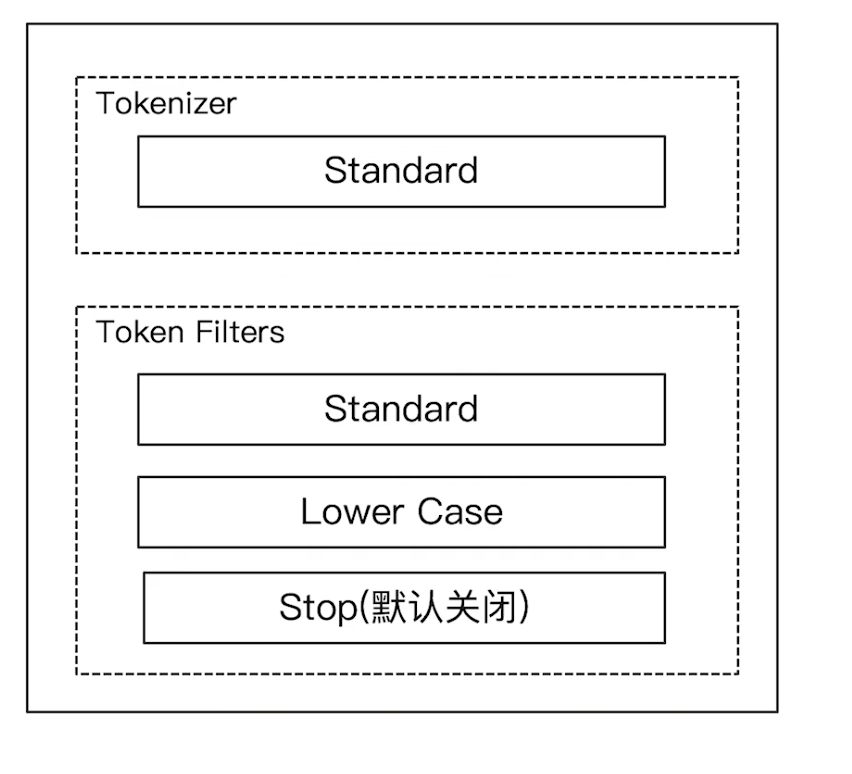
Standard Analyzer
- 默认分词器
- 按词切分
- 小写处理
Keyword Analyzer
- 不分词,直接将一个输入当作一个term输出
中文分词难点
- 中文句子,切分成一个一个词(不是字)
- 英文中,单词有自然的空格作为分隔符
- 一句中文,在不同的上下文中有不同的意义
ICU Analyzer
- 需要安装plugin: E;asticsearch-plugin install analysis-icu
- 提供了Unicode的支持,更好的支持亚洲语言
其他中文分词器
IK
https://github.com/medcl/elasticsearch-analysis-ik
支持自定义词库,支持热更新分词字典
THULAC
https://github.com/microbun/elasticsearch-thulac-plugin
THU Lexucal Analyzer for Chinese,清华大学自然语言处理和社会人文计算实验室的一套中文分词器
自定义分词
当Elasticsearch自带的分词器无法满足时,可以自定义分词器。通过组合不同的组件实现
Character Filter 字符过滤器
在Tokenizer之前对文本进行处理,例如增加删除及替换字符。可以配置多个Character Filters。会影响Tokenizer的position和offset信息
Elasticsearch内置的Character Filters
- HTML strip: 去除HTML标签
- Mapping: 字符串替换
- Pattern replace: 正则匹配替换
1 | POST _analyze |
Tokenizer 分词器
将原始文本按照一定的规则切分为词(term or token)
Elasticsearch内置的的Tokenizers
- whitespace
- standard
- uax_url_email
- pattern
- keyword 不做任何处理
- path hierarchy 文件路径
也可以用JAVA开发插件,实现自己的Tokenizer
Token Filters 词单元过滤器
将Tokenizer输出的单词(term)进行增删改
Elasticsearch内置的Token Filters
- lowercase
- stop
- synonym 添加近义词
设置一个Custom Analyzer
1 | { |

