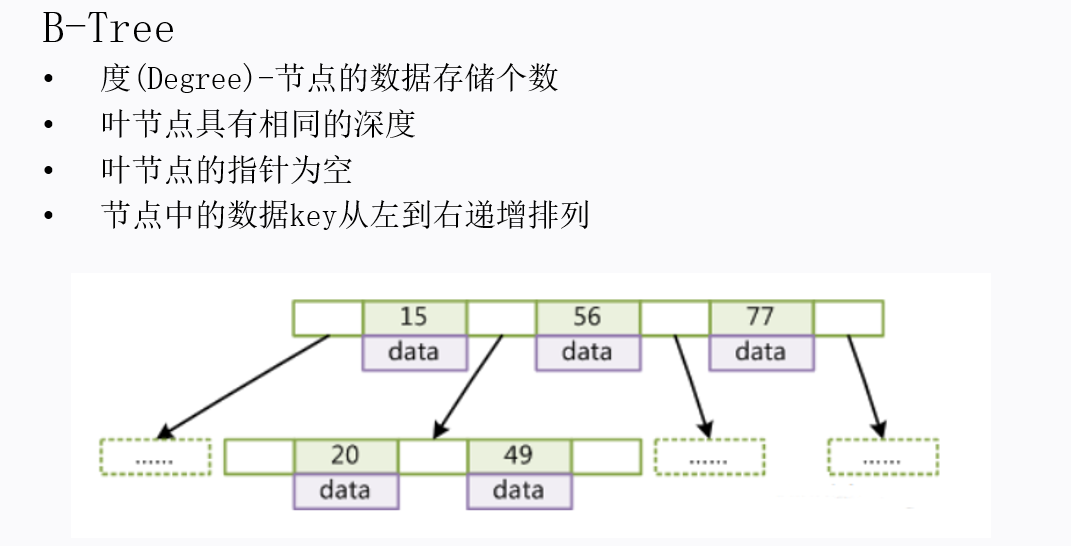
btree、b+tree区别
btree
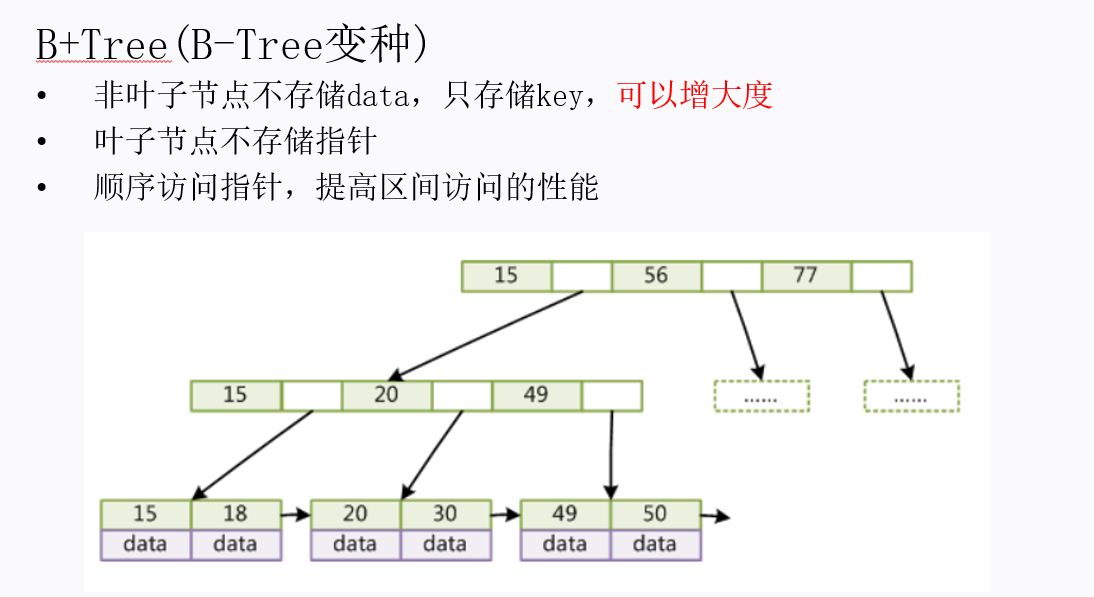
b+tree
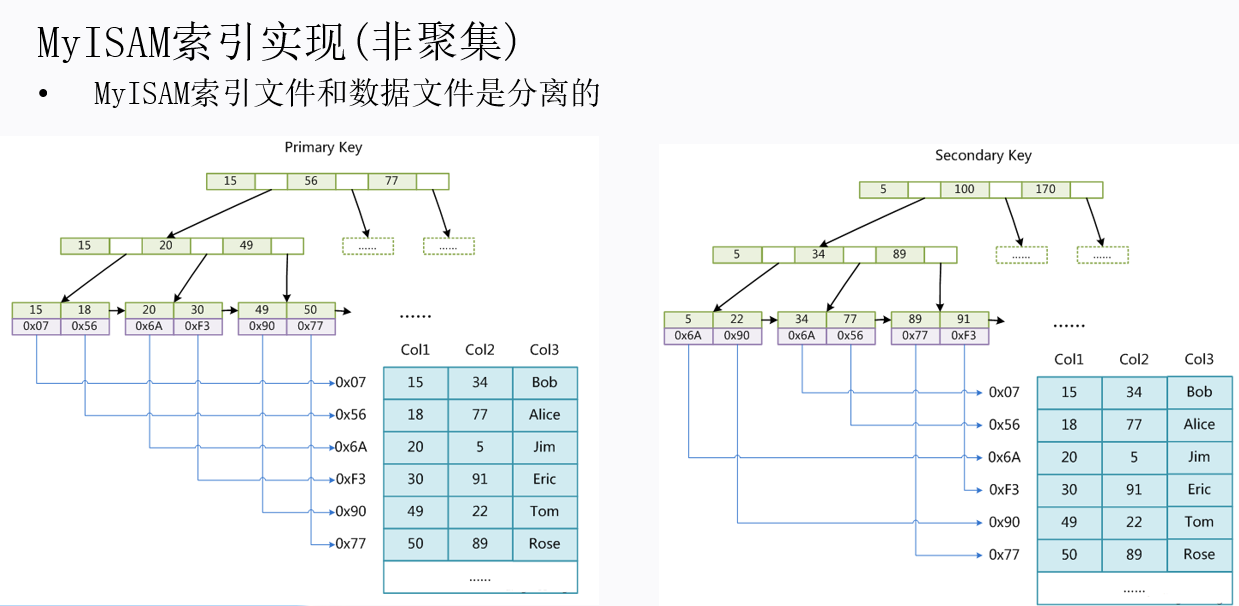
InnoDB、MyISAM区别
MyISAM
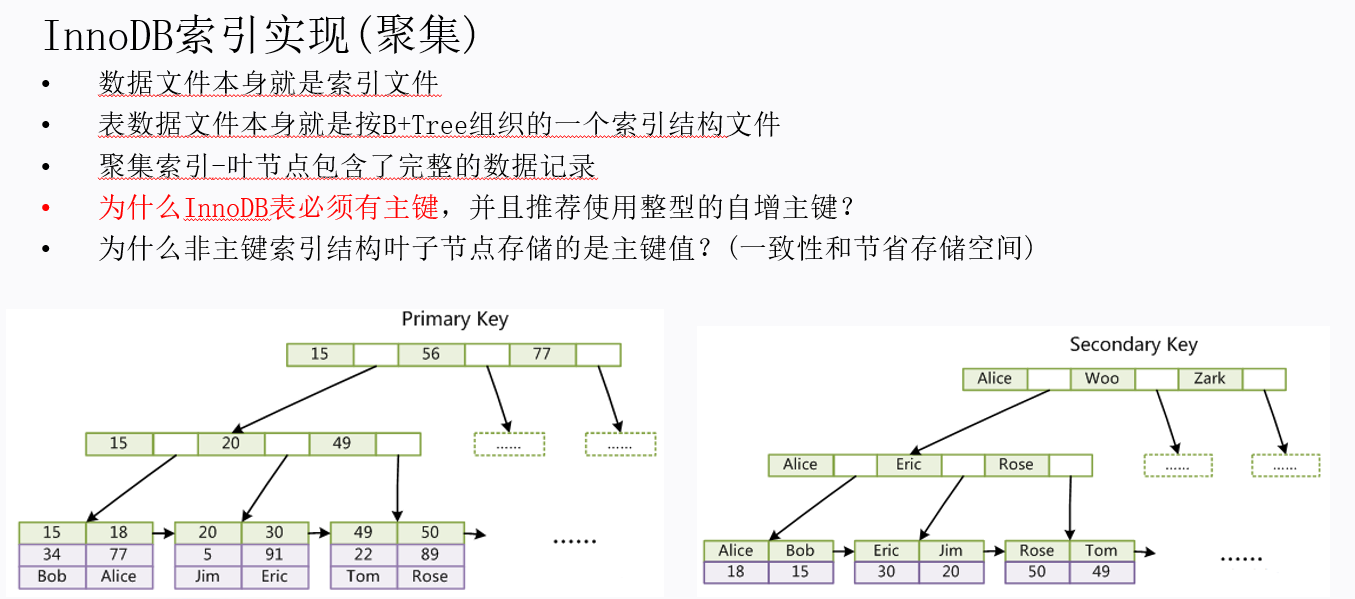
InnoDB
对比表格
| 对比内容 | MyISAM | Innodb | |
|---|---|---|---|
| 存储结构 | 三个文件存储:firm(表定义文件)、myd(数据文件)、myi(索引文件) | 两个文件存储:firm(表定义文件)、idb(数据、索引文件) | |
| 外键 | 不支持 | 支持 | |
| 事务 | 不支持 | 支持 | |
| 锁支持 | 表级锁 | 表、行级锁 | |
| 哈希索引 | 不支持 | 支持 | |
| 全文索引 | 支持 | 不支持 | |
| 记录存储结构 | 按记录插入顺序保存 | 按主键有序保存 | |
| 索引实现方式 | 聚簇索引,堆表 | 非聚簇索引,是索引组织表 | |
| 叶子节点根保存内容 | 行数据地址 | 具体的行数据 |
explain
type
- ALL 扫描全表数据
- index 遍历索引
- range 索引范围查找
- index_subquery 在子查询中使用 ref
- unique_subquery 在子查询中使用 eq_ref
- ref_or_null 对Null进行索引的优化的 ref
- fulltext 使用全文索引
- ref 使用非唯一索引查找数据
- eq_ref 在join查询中使用PRIMARY KEYorUNIQUE NOT NULL索引关联。
extra部分重要解释
- Using index:查询的列被索引覆盖,并且where筛选条件是索引的前导列,是性能高的表现。一般是使用了覆盖索引(索引包含了所有查询的字段)。对于innodb来说,如果是辅助索引性能会有不少提高。
- Using where Using index:查询的列被索引覆盖,并且where筛选条件是索引列之一但是不是索引的前导列,意味着无法直接通过索引查找来查询到符合条件的数据
- Using index condition:与Using where类似,查询的列不完全被索引覆盖,where条件中是一个前导列的范围;
Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
例如 distinct、group by、order by但列未创建索引等情况Using filesort:mysql 会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时mysql会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况下一般也是要考虑使用索引来优化的。
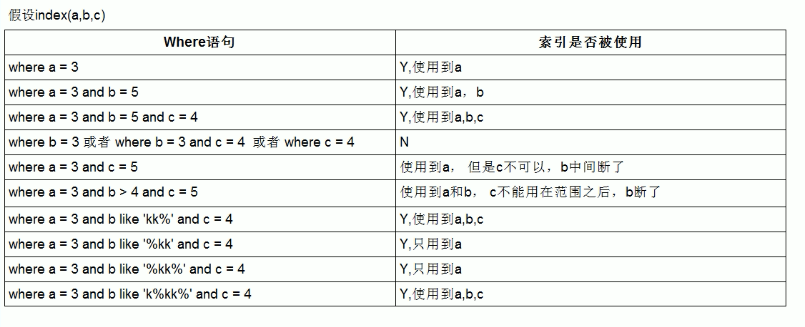
索引优化简单总结
- 全值匹配
- 最佳左前缀法则
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select *语句
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
- is null,is not null 也无法使用索引
like以通配符开头(’$abc…’)mysql索引失效会变成全表扫描操作
问题:解决like’%字符串%’索引不被使用的方法?- 使用覆盖索引,查询字段必须是建立覆盖索引字段
- 当覆盖索引指向的字段是varchar(380)及380以上的字段时,覆盖索引会失效
字符串不加单引号索引失效
- 少用or或in,非主键索引会失效,主键索引有时会生效,用它连接时很多情况下索引会失效
in和exists
mysql中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
- 如果查询的两个表大小相当,那么用in和exists差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in。
- not in 和not exists:如果查询语句使用了not in,那么内外表都进行全表扫描,没有用到索引;而not extsts的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
总结
- MySQL支持两种方式的排序filesort和index,Using index是指MySQL扫描索引本身完成排序。index效率高,filesort效率低。
- order by满足两种情况会使用Using index。
- .order by语句使用索引最左前列。
- .使用where子句与order by子句条件列组合满足索引最左前列。
- 尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最佳左前缀法则。
- 如果order by的条件不在索引列上,就会产生Using filesort。
- group by与order by很类似,其实质是先排序后分组,遵照索引创建顺序的最佳左前缀法则。注意where高于having,能写在where中的限定条件就不要去having限定了。
锁
关闭自动提交模式1
SET AUTOCOMMIT=0;
- START TRANSACTION、BEGIN开启事务
- COMMIT提交当前事务
- ROLLBACK回滚当前事务
锁的分类
- 从性能上分为乐观锁(用版本对比来实现)和悲观锁
- 从对数据库操作的类型,分为读锁和写锁(都属于悲观锁)
- 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响
- 写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁
- 从对数据操作的粒度分,分为表锁和行锁
表锁(偏读)
表锁偏向MyISAM存储引擎,开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发度最低
手动增加表锁1
lock table 表名称 read(write),表名称2 read(write);
查看表上加过的锁1
show open tables;
删除表锁1
unlock tables;
读锁
- 当前session和其他session都可以读该表
- 当前session中插入或者更新锁定的表都会报错
- 其他session插入或更新则会等待
写锁
- 当前session对该表的增删改查都没有问题
- 其他session对该表的所有操作被阻塞
小结
MyISAM在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行增删改操作前,会自动给涉及的表加写锁。
- 对MyISAM表的读操作(加读锁) ,不会阻寒其他进程对同一表的读请求,但会阻赛对同一表的写请求。只有当读锁释放后,才会执行其它进程的写操作。
- 对MylSAM表的写操作(加写锁) ,会阻塞其他进程对同一表的读和写操作,只有当写锁释放后,才会执行其它进程的读写操作
简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁则会把读和写都阻塞。
行锁(偏写)
行锁偏向InnoDB存储引擎,开销大,加锁慢,会出现死锁,锁定粒度最小,发生锁冲突的概率最低,并发度也最高。InnoDB与MYISAM的最大不同有两点:一是支持事务(TRANSACTION);二是采用了行级锁。
ACID、和事务四种隔离级别,带来的三种问题就不写了。
常看当前数据库的事务隔离级别:1
show variables like 'tx_isolation';
设置事务隔离级别:1
set tx_isolation='REPEATABLE-READ';
可重复读的隔离级别下使用了MVCC机制,select操作不会更新版本号,是快照读(历史版本);insert、update和delete会更新版本号,是当前读(当前版本)。
mysql中事务隔离级别为serializable时会锁表,因此不会出现幻读的情况,这种隔离级别并发性极低,开发中很少会用到。
间隙锁
1 | update table_name set id > start and id < end ; |
这时如果其他的session执行insert或update id= start和end区间的数据,就会阻塞
锁分析
通过检查InnoDB_row_lock状态变量来分析系统上的行锁的争夺情况1
show status like'innodb_row_lock%';
对各个状态量的说明如下:
- Innodb_row_lock_current_waits: 当前正在等待锁定的数量
- Innodb_row_lock_time: 从系统启动到现在锁定总时间长度
- Innodb_row_lock_time_avg: 每次等待所花平均时间
- Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花时间
- Innodb_row_lock_waits:系统启动后到现在总共等待的次数
对于这5个状态变量,比较重要的主要是:
- Innodb_row_lock_time_avg (等待平均时长)
- Innodb_row_lock_waits (等待总次数)
- Innodb_row_lock_time(等待总时长)
尤其是当等待次数很高,而且每次等待时长也不小的时候,我们就需要分析系统中为什么会有如此多的等待,然后根据分析结果着手制定优化计划。
死锁
相互等待即会产生死锁 wait-for graph
查看近期死锁日志信息1
show engine innodb status;
大多数情况mysql可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况mysql没法自动检测死锁
关于锁的优化
- 尽可能让所有数据检索都通过索引来完成,避免无索引行锁升级为表锁
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少检索条件,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽可能低级别事务隔离

