记录下关于分布式ID相关知识点
分布式ID基本要求
- 全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
- 分布式id里面最好包含时间戳,这样就能够在开发中快速了解这个分布式id的生成时间。
上述的基本要求中,3和4点其实是互斥的,要根据实际业务要求来进行判断。
生成方案
其实主要有两种方式生成,一种是根据某种算法组合生成,另外一种是依赖数据库、缓存中间件、ZK等协助生成。下面分别介绍下几种常见的生成方式。
snowflake
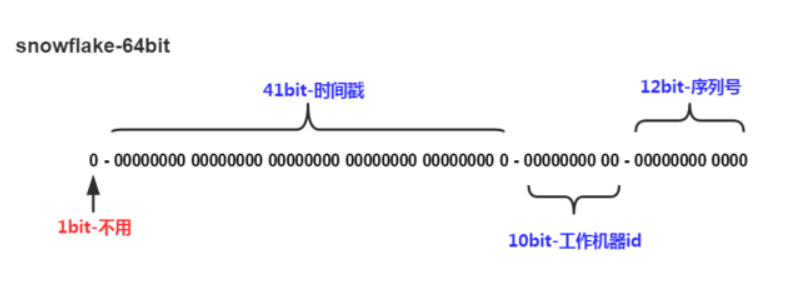
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID),最后还有一个符号位,由于ID大都为正数,所以是0。
时间回拨问题
由于snowflake是包含时间戳组成的,如果出现了部署服务器时间回退的问题,则可能会产生重复的id。一般情况下生产环境的机器是不会随意调整时间的,但是也可能会出现特殊情况,需要对此做一些应对。
每个时间段下,并不一定会在该时间段内生成达到上限,所以一定会在该短时间内有大量的id被浪费。这些被浪费的资源就可以利用起来。
比如在内存中保存每个时间戳的生成id,在发生时间回拨的时候,取上一次时间最后记录的id对序列部分进行+1使用。
也可以利用扩展位,因为snowflake算法的极限是每毫秒的每一个节点生成4059个id值,也就是说每毫秒的极限是生成023*4059=4 152 357个id值,这对于中小公司来说根本就是浪费,所以我们可以把这里的位数给减少一些,就比如把12位的序列号变成10位,留两位给时间回拨,这样就很容易的解决了时间回拨问题,如果发生时间回拨,那么就直接给当前id加1。
UUID
通用唯一标识符(UUID)是一个128位的用于在计算机系统中以识别信息的数目。通常在Microsoft创建的软件中也使用术语全球唯一标识符(GUID)。
在其规范的文本表示形式中,UUID 的16 个八位字节表示为32个十六进制(基数16)数字,以5个组显示,由连字符分隔,格式为8-4-4-4-12,共36个字符(32个字母数字字符和4个连字符)。例如:1
2123e4567-e89b-12d3-a456-426655440000
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
4位M和1到3位N字段编码UUID本身的格式。数字的4位M是UUID版本,数字的1至3个最高有效位对NUUID变体进行编码。(请参见下文。)在示例中,M为1,N为a(10xx 2),这意味着这是版本1,版本1的UUID。即基于时间的DCE/RFC 4122 UUID。
规范的8-4-4-4-12格式字符串基于UUID的16个字节的记录布局:
UUID记录布局
| 名称 | 长度(字节) | 长度(十六进制数字) | 内容 |
|---|---|---|---|
| time_low | 4 | 8 | 给出时间的低32位的整数 |
| time_mid | 2 | 4 | 给出时间的中间16位的整数 |
| time_hi_and_version | 2 | 4 | 最高有效位为4位“版本”,然后是时间的高12位 |
| clock_seq_hi_and_res clock_seq_low | 2 | 4 | 最高有效位为1至3位“变量”,随后为13至15位时钟序列 |
| 节点 | 6 | 12 | 48位节点ID |
JDK提供的工具类
可以直接使用java.util.UUID来生成UUID1
2
3public static void main(String[] args) {
System.out.println(UUID.randomUUID().toString().replace("-", "").toLowerCase());
}
UUID是否适合做分布式ID
如果需求是只保证唯一性,那么UUID也是可以使用的,但是按照上面的分布式id的要求, UUID其实是不能做成分布式id的,原因如下:
- 首先分布式id一般都会作为主键,但是安装mysql官方推荐主键要尽量越短越好,UUID每一个都很长,所以不是很推荐
- 既然分布式id是主键,然后主键是包含索引的,然后mysql的索引是通过b+树来实现的,每一次新的UUID数据的插入,为了查询的优化,都会对索引底层的b+树进行修改,因为UUID数据是无序的,所以每一次UUID数据的插入都会对主键地城的b+树进行很大的修改,这一点很不好
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。

