又开了一个坑,之前也只是对ES和ELK的使用和搭建只有简单的理解,没有系统的学习过,那趁着这段时间好好系统的学习下。
全部学习笔记内容摘自极客时间阮一鸣老师的视频课程《Elasticsearch核心技术与实战》,与书籍《深入理解elasticsearch》。但后者相较于已经对es有初步的认识了,适合进阶学习。
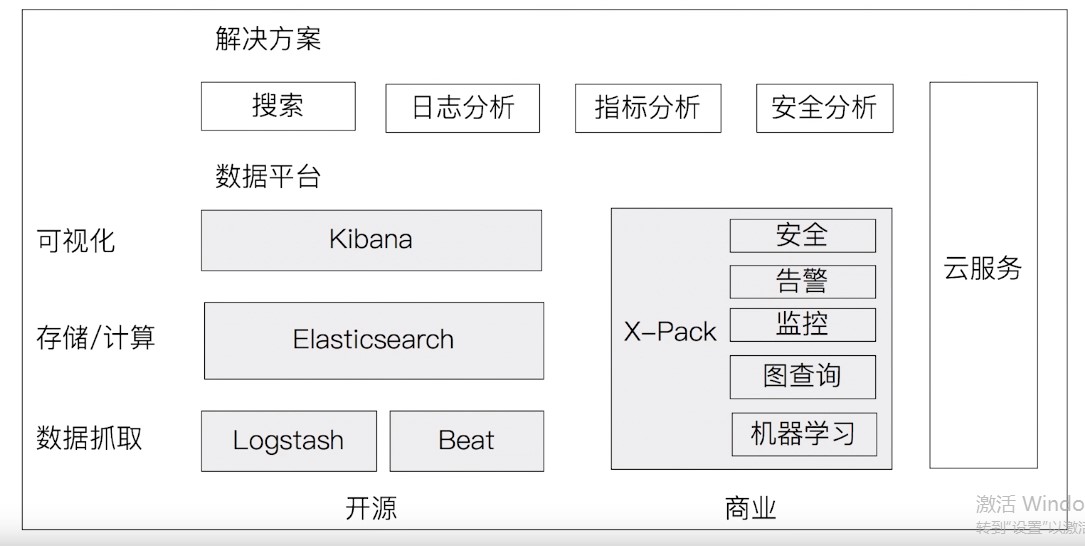
ElasticSearch 基于JSON的开源分布式搜索分析引擎
- Near Real Time 近实时
- 分布式存储/搜索/分析引擎
同类产品
- solr(Apache开源项目)
- splunk(商业上市公司)
Elastic Stack
- Kibana 数据可视化
- Logstash 动态数据收集管道
- Beats 轻量型数据采集器
起源
Lucene
初创于1999年,Apache开源项目,基于JAVA语言开发
- Lucene具有高性能、易扩展的优点
- Lucene的局限性:
- 只能基于JAVA语言开发
- 类库的接口学习曲线陡峭
- 原生并不支持水品扩展
Elasticsearch的诞生
- 2004年Shay Banon基于Lucene开发了Compass
- 2010年Shay Banon对Compass进行了重写,更名为Elasticsearch
- 支持分布式、可水平扩展
- 提供Restful Api,降低全文检索的学习曲线。并且可接入任何语言应用。
Elasticsearch的分布式架构
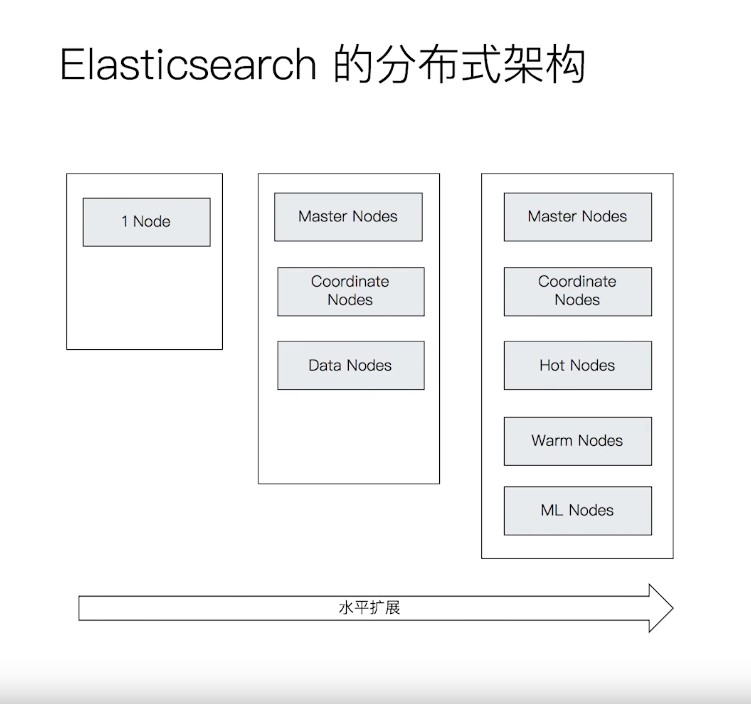
- 集群规模可以从单个扩展至数百个节点
- 高可用&水平扩展,从服务和数据两个维度
- 支持设置不同的节点类型,支持Hot&Warm架构
支持多种方式介接入
- 多种语言接入类库
- RESTful api & Transport Api
- JDBC & ODBC
Elasticsearch主要功能
- 海量数据的分布式存储以及集群管理
- 服务与数据的高可用、水平扩展
- 近实时搜索,性能卓越
- 结构化/全文/地理位置/自动完成
- 海量数据的近实时分析
- Lucene 6.x,性能提升,默认打印机制从TF-IDF改为BM25
- 支持Ingest节点/Painless Scripting/Completiion suggested支持/原生的Java REST客户端
- Type标记成deprecated,支持了Keyword的类型
- 性能优化
- 内部引擎移除了避免同一文档并发更新的竞争锁,带来了15%-20%的性能提升
- Instant aggregation,支持分片上的聚合的缓存
- 新增了Profile API
6.x
- Lucene 7.x
- 新特性
- 跨集群复制(CCR)
- 索引生命周期管理
- SQL的支持
- 更友好的升级以及数据迁移
- 在主要版本之间的迁移更加简化,体验升级
- 全新的基于操作的数据复制框架,可加快恢复数据
- 性能优化
- 有效存储稀疏字段的新方法,降低了存储成本
- 在索引时进行排序,可加快排序的查询性能
7.x
- Lucene 8.0
- 重大改进-正式废除单个索引下多Type的支持
- 7.1开始,Security功能免费使用
- ECK-Elasticsearch Operator on Kubernetes,可以将Elasticsearch部署至K8S的容器环境中
- 新功能
- New Cluster coordinatio,新的分组协调
- Feature-Complete High Level REST Client,改进了高级REST客户端
- Script Score Query
- 性能优化
- 默认的Primary Shard数由5改为1,避免over sharding
- 性能优化,更快的Top K
Elastic Stack生态圈
基于Elaticsearch、Logstash、Kibana等构建出一整套的生态系统,适合大量场景,向用户提供网站搜索、机器学习等服务。
Logstash 数据处理管道
开源的服务端数据处理管道,支持从不同来源采集数据、转换数据,并将数据发送到不同的存储介质中。
Logstash诞生于2009年,最初用作日志的的采集与处理,后再2013年被Elastic收购。
特性
- 实时解析和转换数据
- 从IP地址破译出地理坐标
- 将PII数据匿名化,完全排除敏感字段
- 可扩展
- 200多个插件(日志/数据库/Arcsigh/Netflow)
- 可靠性安全性
- Logstash会通过持久化队列来保证至少将运行中的事件送达一次
- 数据传输加密
- 监控
Kibana 可视化分析
Kibana = Kiwifruit(奇异果) + banana(香蕉)
数据可视化工具,最初基于Logstash,2013年被Elastic公司收购。
数据可视化分析,kibana可以提供一系列的可视化图表。也可以结合机器学习的技术做一些相关异常检测,提前发现可疑的问题。
Beats 轻量的数据采集器
Go语言开发,运行速度快。
- Filebeat:文件采集器
- Packetbeat:网络数据抓包
- functionbeat:对serveriess infrastructure提供数据抓取
- winlogbeat
- Metricbeat
- Heartbeat
- Auditbeat
- Journalbeat
ELK应用场景
- 网站搜索/垂直搜索/代码搜索
- 日志管理与分析/安全指标监控/应用性能监控/WEB抓取舆情分析
搜索场景
ElasticSearch与数据库的集成
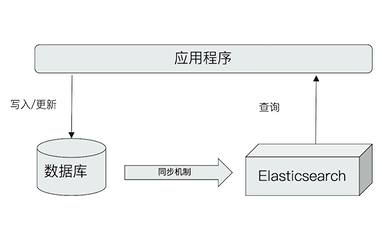
- 可以单独使用Elasticsearch进行单存储。但是当数据需要与现有数据集成、考虑事务性、数据频繁更新时,就需要与数据库进行同步数据了。
指标分析/日志分析
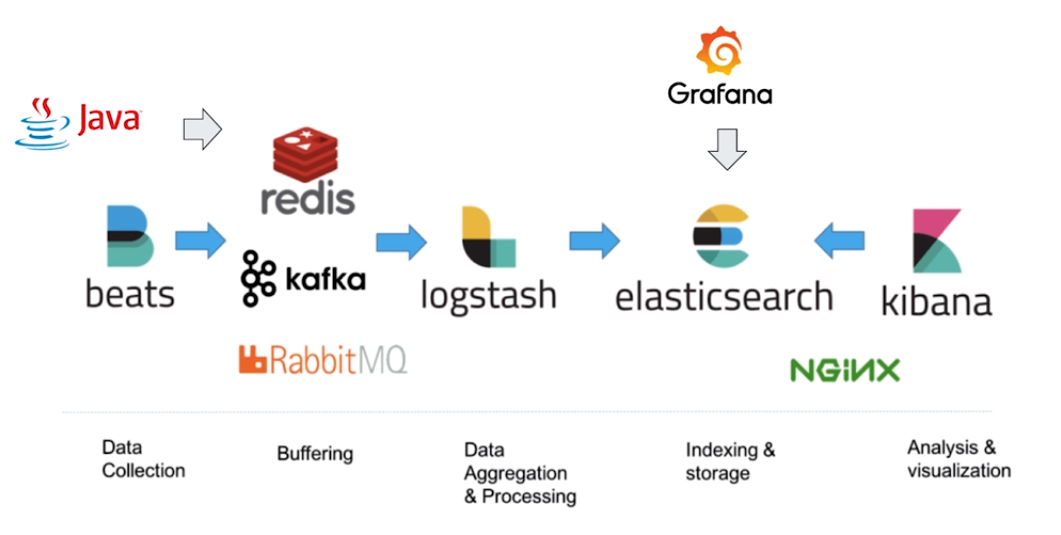
- Data Collection,收集数据。beats可以从不同的数据源中收集数据。对于特定的需求,可以通过代码实现数据收集。
- Buffering,缓冲。在真实的业务场景中,往往需要收集的数据量较大
,需要引入消息、缓存中间件来作为数据采集的缓冲层。 - Data Aggregation&Processing,数据转化聚合后发送给ES。
- Indexing&Storage,索引和存储。
- Analysis&visualization,基于Elasticsearch可以搭建Kibana,也可以使用可Grafana进行数据分析,图形化展示。

