今天工作中遇到了关于使用parallelStream导致的并发安全问题,使用三个ArrayList容器进行数据交集等处理时,由于数据较多,希望通过并行流提高处理效率,但没考虑过线程安全问题。
解决的方法非常简单,正确的使用map、collect、reduce,或者使用线程安全容器、加锁即可。
但其实是使用时没有仔细了解相关的使用知识导致应用出现问题。搜了下确实有很多相关资料,需要仔细了解相关API的使用才可以避免相关问题的出现。
本文内容全部摘自其他博客等文章内容,具体地址在本文结尾。
背景
Java8的stream接口极大地减少了for循环写法的复杂性,stream提供了map/reduce/collect等一系列聚合接口,还支持并发操作:parallelStream。
在爬虫开发过程中,经常会遇到遍历一个很大的集合做重复的操作,这时候如果使用串行执行会相当耗时,因此一般会采用多线程来提速。Java8的paralleStream用fork/join框架提供了并发执行能力。但是如果使用不当,很容易陷入误区。
Java8的paralleStream是线程安全的吗
先来两个简单的例子1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35public class ParallelStreamTest {
private static final int COUNT = 1000;
public static void main(String[] args) {
List<RiderDto> orilist = new ArrayList<RiderDto>();
for (int i = 0; i < COUNT; i++) {
orilist.add(init());
}
final List<RiderDto> copeList = new ArrayList<RiderDto>();
orilist.parallelStream().forEach(rider -> {
RiderDto t = new RiderDto();
t.setId(rider.getId());
t.setCityId(rider.getCityId());
copeList.add(t);
});
System.out.println("orilist size:" + orilist.size());
System.out.println("copeList size:" + copeList.size());
System.out.println("compare copeList and list,result:" + (copeList.size() == orilist.size()));
}
private static RiderDto init() {
RiderDto t = new RiderDto();
Random random = new Random();
t.setId(random.nextInt(2 ^ 20));
t.setCityId(random.nextInt(1000));
return t;
}
static class RiderDto implements Serializable {
private static final long serialVersionUID = 1;
private Integer cityId;
private Integer id;
}
}
多次运行输出如下:1
2
3
4
5
6
7
8
9
10
11orilist size:1000
copeList size:998
compare copeList and orilist,result:false
orilist size:1000
copeList size:981
compare copeList and orilist,result:false
orilist size:1000
copeList size:1000
compare copeList and orilist,result:true
1 | Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException |
在下面的代码中采用stream的forEach接口对1-10000进行遍历,分别插入到3个ArrayList中。其中对第一个list的插入采用串行遍历,第二个使用paralleStream,第三个使用paralleStream的同时用ReentryLock对插入列表操作进行同步:
1 | private static List<Integer> list1 = new ArrayList<>(); |
执行结果:1
2
3串行执行的大小:10000
并行执行的大小:9595
加锁并行执行的大小:10000
parallelStream是一个并行执行的流,其使用 fork/join (ForkJoinPool)并行方式来拆分任务和加速处理过程。研究parallelStream之前,搞清楚ForkJoinPool是很有必要的。
ForkJoinPool的核心是采用分治法的思想,将一个大任务拆分为若干互不依赖的子任务,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务。同时,为了最大限度地提高并行处理能力,采用了工作窃取算法来运行任务,也就是说当某个线程处理完自己工作队列中的任务后,尝试当其他线程的工作队列中窃取一个任务来执行,直到所有任务处理完毕。所以为了减少线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
到这里,我们知道parallelStream使用多线程并行处理数据,关于多线程,有个老生常谈的问题,线程安全。正如上面的分析,demo中list会被拆分为多个小任务,每个任务只负责处理一小部分数据,然后多线程并发地处理这些任务。问题就在于ArrayList不是线程安全的容器,并发调用add就会发生线程安全的问题。
那么既然paralleStream不是线程安全的,是不是在其中的进行的非原子操作都要加锁呢?我在stackOverflow上找到了答案:
- https://codereview.stackexchange.com/questions/60401/using-java-8-parallel-streams
- https://stackoverflow.com/questions/22350288/parallel-streams-collectors-and-thread-safety
在上面两个问题的解答中,证实paralleStream的forEach接口确实不能保证同步,同时也提出了解决方案:使用collect和reduce接口。
在Javadoc中也对stream的并发操作进行了相关介绍:1
The Collections Framework provides synchronization wrappers, which add automatic synchronization to an arbitrary collection, making it thread-safe.
Collections框架提供了同步的包装,使得其中的操作线程安全。
所以下一步,来看看collect接口如何使用。
stream的collect接口
闲话不多说直接上源码吧,Stream.java中的collect方法句柄:1
<R, A> R collect(Collector<? super T, A, R> collector);
在该实现方法中,参数是一个Collector对象,可以使用Collectors类的静态方法构造Collector对象,比如Collectors.toList(),toSet(),toMap(),etc,这块很容易查到API故不细说了。
除此之外,我们如果要在collect接口中做更多的事,就需要自定义实现Collector接口,需要实现以下方法:1
2
3
4
5Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
要轻松理解这三个参数,要先知道fork/join是怎么运转的,一图以蔽之:
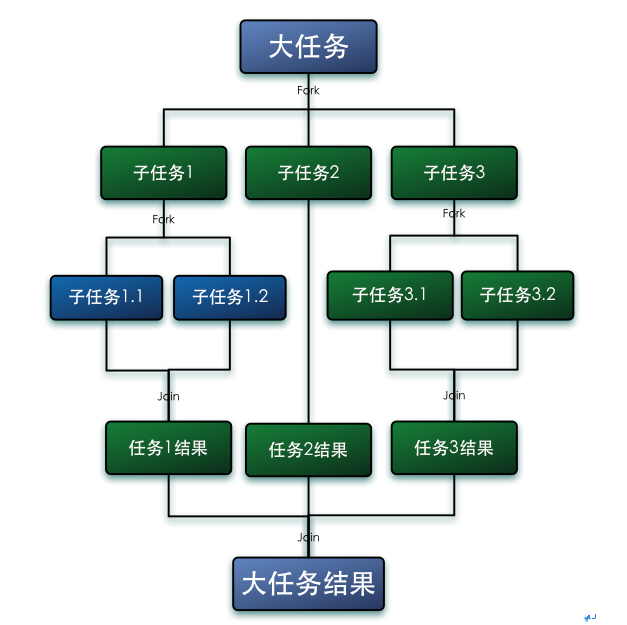
简单地说就是大任务拆分成小任务,分别用不同线程去完成,然后把结果合并后返回。所以第一步是拆分,第二步是分开运算,第三步是合并。这三个步骤分别对应的就是Collector的supplier,accumulator和combiner。talk is cheap show me the code,下面用一个例子来说明:
输入是一个10个整型数字的ArrayList,通过计算转换成double类型的Set,首先定义一个计算组件:
Compute.java:1
2
3
4
5public class Compute {
public Double compute(int num) {
return (double) (2 * num);
}
}
接下来在Main.java中定义输入的类型为ArrayList的nums和类型为Set的输出结果result:1
2private List<Integer> nums = new ArrayList<>();
private Set<Double> result = new HashSet<>();
定义转换list的run方法,实现Collector接口,调用内部类Container中的方法,其中characteristics()方法返回空set即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public void run() {
// 填充原始数据,nums中填充0-9 10个数
IntStream.range(0, 10).forEach(nums::add);
//实现Collector接口
result = nums.stream().parallel().collect(new Collector<Integer, Container, Set<Double>>() {
public Supplier<Container> supplier() {
return Container::new;
}
public BiConsumer<Container, Integer> accumulator() {
return Container::accumulate;
}
public BinaryOperator<Container> combiner() {
return Container::combine;
}
public Function<Container, Set<Double>> finisher() {
return Container::getResult;
}
public Set<Characteristics> characteristics() {
// 固定写法
return Collections.emptySet();
}
});
}
构造内部类Container,该类的作用是一个存放输入的容器,定义了三个方法:
- accumulate方法对输入数据进行处理并存入本地的结果
- combine方法将其他容器的结果合并到本地的结果中
- getResult方法返回本地的结果
Container.java:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class Container {
// 定义本地的result
public Set<Double> set;
public Container() {
this.set = new HashSet<>();
}
public Container accumulate(int num) {
this.set.add(compute.compute(num));
return this;
}
public Container combine(Container container) {
this.set.addAll(container.set);
return this;
}
public Set<Double> getResult() {
return this.set;
}
}
在Main.java中编写测试方法:1
2
3
4
5
6
7
8public static void main(String[] args) {
Main main = new Main();
main.run();
System.out.println("原始数据:");
main.nums.forEach(i -> System.out.print(i + " "));
System.out.println("\n\ncollect方法加工后的数据:");
main.result.forEach(i -> System.out.print(i + " "));
}
输出:1
2
3
4
5原始数据:
0 1 2 3 4 5 6 7 8 9
collect方法加工后的数据:
0.0 2.0 4.0 8.0 16.0 18.0 10.0 6.0 12.0 14.0
我们将10个整型数值的list转成了10个double类型的set,至此验证成功~
一言蔽之
总结就是paralleStream里直接去修改变量是非线程安全的,但是采用collect和reduce操作就是满足线程安全的了。

