来自公司同事压测性能调优的分享
前情提要
完美中国项目进入压测环节,就是业务都做完啦,通过压测优化让系统性能达到设计标准,通过客户验收即可交付。这边有几个平衡点
- 总体预算大体不变的框架下进行资源分配优化
- 大体需求不变的前提下做功能效率优化
基于这两点,盲目说
性能不够加机器,砍功能说无法实现都是不可以的,压测的目的就是要攻克难关。
优化场景
数据同步效率优化
从问题出发
- mysql数据为什么要同步到es?
设计
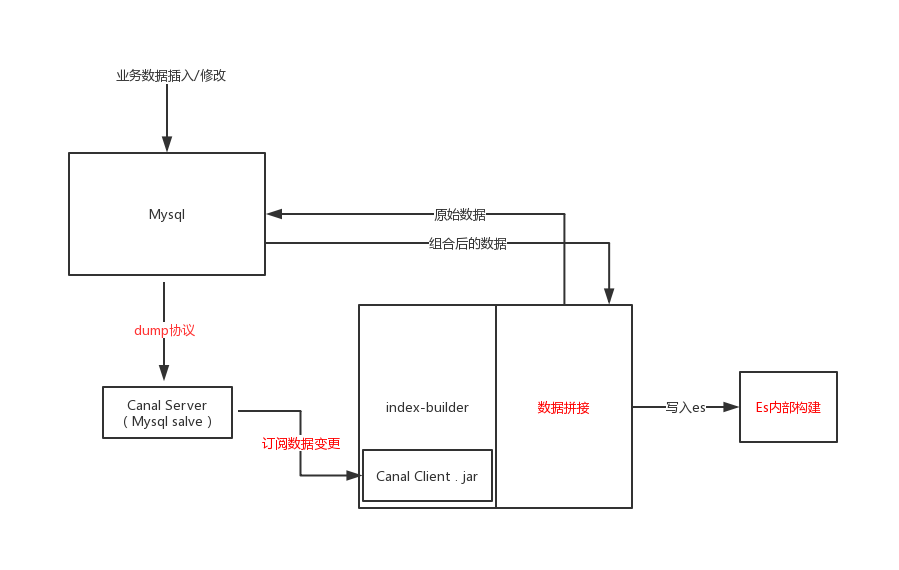
可能的瓶颈点
(红字处
优化手段
- 对数据进行多线程分片执行,对数据集进行分片,每个分片由单独线程执行,充分利用多核CPU的优势。
++原先一个大表(2000w+数据)全量同步需要20+h,优化后在1h内同步完成++
示例代码(非可执行代码)
1 | public class IndexExecutor<K, T>{ |
以上代码的核心点
获取分片边界 long[] splitShard(int shardNums, long total)
取数据时按where取数据,而不是limit取数据,可以命中拆分键(存疑。。
线程池 & JVM最佳线程数量 cpu核数 * 1.5 (存疑。。
SQL调优
- 减少数据库交互次数
++原先一次数据组装耗时100s-500s不可控,优化后稳定在1s左右++
查询数据库的过程如果涉及for循环,看是否可以修改for循环取数据为in查询,减少数据库交互次数
原先
1 | for (UserDto docValue : docValues) { |
优化后
1 | String personIds = docValues.stream() |
同库情况下使用join代替多次数据库查询。用子查询优化主表,核心是先筛选,再join。减少表关联的数量级。
1 | SELECT |
- 把多数据源聚合的过程的同步调用异步化
原来代码
1 | /** |
优化后
1 | /** |
- 避免跨库关联数据
++数据库是DRDS,数据量大概在3亿+,预计2年内增量到5亿+。优化前数据库超时导致基本不可执行,优化后可正常导数据++
DRDS海量数据导入ES的策略优化,DRDS对调用层隐藏了分库分表的复杂性,方便了方法调用的统一,但因为对调用者透明,开发同学很容易无意间写出全库扫描的sql,反而降低了效率。在我们数据迁移的场景中,需要扫描所有数据做全量迁移,所以这里先列出所有数据库,针对具体的库并行调用扫描提高效率。
1 | 列出所有分库 |
其他工作
- 增强组件对shardingJDBC分表扫描特性
- 业务功能:优惠券、收货地址建立索引等
总结
方法论
- 沿着业务的逻辑线路梳理流程节点,针对节点之间的通路,节点内部,用可量化的标准,找出瓶颈并优化。
- 充分利用多核CPU的性能,多做并行处理
- 使用批量调用接口替代单次调用接口,减少性能损耗
- 优化SQL join的数量级(并非列举所有优化策略,仅仅是讲在此次完美压测用到的部分内容)
其他大佬的建议
- 线程池资源释放没有处理;
- 建议采用callable与futrueTask;
- 数据同步锁;
- DB IO峰值检测;
- ES分片

