线程模型分享 (上)
本篇文章是公司大佬约拿上周五给我培训的文档,分享给大家。非常感谢百忙之中给我培训。
引言
为什么有这篇文章?
起先看我的目标是看netty的线程模型,但是在看netty的过程中,我发现很多知识点是互相关联的。比如netty的EventLoop,EventLoopGroup其实是继承自JDK的线程池。学习netty的线程模型前需要懂得预备知识。基于这个理由,我把预备内容部分也写下来。分享一共会分为上下两篇,这里是第上篇,这篇主要是先导,给【下篇】的知识打基础,有了上篇的基础再看下篇就容易多了。
这篇文章会有什么内容?
- JDK线程池的类继承层次
- 构建线程池的几个核心要素
- JDK线程池关键方法的分析
- JDK线程池存在的问题
- 常见的线程模型举例
- 线程模型适用场景分析
- 线程竞争与锁
文章目的
- 可以自定义JDK线程池,了解JDK线程池的局限场景
- 了解线程模型的原理及适用场景
- 了解锁的目的及分类
线程启动与停止
如何启动线程
这个比较基础的不说了
如何停止线程
- 线程类有stop,suspend方法,但是被弃用了。
- stop 会立即杀死线程,可能导致执行一半的程序被终结导致数据不一致的风险
- suspend 会挂起线程,但是不会释放锁,可能会造成死锁
- 线程池有个 shutdown 方法只是阻止线程池接受新的线程 ,并不会停止已存在的线程。
- 正确的方法
- 线程自己运行完成
- 设置终止标志,在循环中检查这个标志
JDK线程池继承层次
结构图

这个图上很多类不用看,因为都是Executors类的内部类,代理类,核心就是下图的几个接口和类。

线程池核心要素
核心线程池大小 corePoolSize
设置一个线程池中的核心线程数 如果设置allowCoreThreadTimeOut为false的情况下: 即使当线程池中的线程处于空闲状态,这些线程也不会被线程池中移除。 如果设置了allowCoreThreadTimeOut为true, 那么当核心线程在空闲了一段时间后依旧没有用于工作,那么将会从线程池中移除。 注意:(allowCoreThreadTimeOut默认为false,通常情况下也无需做修改)
线程保持活跃时间
keepAliveTime:当线程池中的线程数量大于核心线程数,如果这些多出的线程在经过了keepAliveTime时间后,依然处于空闲状态,那么这些多出的空闲线程将会被结束其生命周期。
时间单位unit
keepAliveTime的时间单位
最大线程池大小 maximumPoolSize
线程池中所允许创建最大线程数量,除了受JVM内存大小限制外,Linux下还受/proc/sys/kernel/pid_max(即系统允许的最大pid)、/proc/sys/kernel/threads-max(系统支持的最大线程数)、max_user_process(ulimit-u)(每个用户允许的最大进程数)、/proc/sys/vm/max_map_count(Linux支持虚拟内存,也就是交换空间,可以把磁盘的一部分作为RAM的扩展,逻辑存储和物理存储的映射就要保存在地址映射表中。max_map_count限制了线程可以拥有的VMAs )
拒绝策略handler
当线程池中的线程数量达到最大并且阻塞队列也已经满了无法再添加任务时,线程池所采取的处理策略,JDK有四种内建的拒绝策略,下面会讲到。
等待队列workQueue
用于存放任务的阻塞队列,当线程池中的核心线程都处在执行任务时,提交的任务将被存储在workQueue进行缓冲。该队列只能存放通过execute方法提交的Runnable任务,如果是个ScheduledThreadPoolExecutor,那么这个队列不仅需要阻塞,而且还是个优先队列。
核心代码分析
ThreadPoolExecutor 一个根正苗红的线程池继承类。
我们看看他的excute方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52这里是调用
int corePoolSize = 1;
int maximumPoolSize = 2;
long keepAliveTime = 60;
TimeUnit unit = TimeUnit.SECONDS;
BlockingQueue<Runnable> workQueue = new LinkedBlockingDeque<>();
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime
, unit, workQueue, Executors.defaultThreadFactory(), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
});
threadPoolExecutor.execute(new Runnable() {
@Override
public void run() {
System.out.println("execute!");
}
});
=========================
看看execute的源码
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// workerCountOf 从ctl中取工作线程的数量,这里有一定的技巧性,下面详细讲一下
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 看当前线程池状态是否Running,这里也是从ctl取值,有点意思
// 把任务用offer方法塞进工作队列,如果插入成功,则返回ture
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 二次检查线程池状态是否为Running,以及从任务队列获取当前任务是否成功
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
// addWorker方法里通过两个for循环通过ctl判断线程池的当前状态是否能新增线程,通过CAS机制修改线程池状态。最后新建worker对象,插入worker队列。
addWorker(null, false);
}
// 线程池的线程数量不够了,增加线程,增加失败的话就拒绝这次execute调用
else if (!addWorker(command, false))
// reject方法里其实是调用定义线程池的时候构造函数传入的handler,JDK内建了四个拒绝策略AbortPolicy、DiscardPolicy、DiscardOldestPolicy、CallerRunsPolicy,含义分别是:抛出RejectedExecutionException异常、直接忽略提交的任务、把之前提交的任务移除,添加新的任务、让当前线程直接处理这个任务。用户也可以实现RejectedExecutionHandler接口,完成自己的拒绝策略。
reject(command);
}DefaultThreadFactory
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
// 核心是这个newThread方法
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}ctl是如何存储线程状态和数量的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20定义
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
上面那串定义看了可能有点懵,源码中使用了一个AtomicInteger对将当前线程的工作状态和工作线程数量(有效线程数)使用同一个整数进行包装。
为了将两个数值包装在同一个整数中,它将32位的高3位表示线程的状态值,而后29位来表示线程的数量。
其实这样设计的理由很简单,因为线程的状态和数量往往需要同时更新,然而线程池天生处在一个并发的环境下,那么当对2个变量进行修改时,那么就势必需要通过锁来进行线程安全的处理,从而保证2个变量修改具备原子性;但是这种做法对于性能的影响是非常严重的,因此在ThreadPoolExecutor将两个变量的分别包装在一个变量中,最后的并发操作发生在AtomicInteger上,而AtomicInteger恰恰就是具有一个无锁原子操作类,这样既可以解决线程安全的问题,又可以规避避免所的使用,从而提供性能。ScheduledThreadPoolExecutor如何实现调度
1
2TODO
优先队列
JDK线程池存在的问题
- FixedThreadPool 和 SingleThreadPool 允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
- CachedThreadPool 和 ScheduledThreadPool允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
- 多线程并行处理定时任务时,Timer运行多个TimeTask时,只要其中之一没有捕获抛出的异常,其它任务便会自动终止运行,使用 ScheduledExecutorService 则没有这个问题。
- ScheduledExecutorService并发执行大量调度时候有瓶颈,大并发量的线程调度应该用时间环模式。
不要感觉自己写几千行的类是很烂的代码,ThreadPoolExecutor也有2100多行(含注释)
线程竞争
线程竞争的定义
在多线程中,每个线程的执行顺序,是无法预测不可控制的,那么在对数据进行读写的时候便存在由于读写顺序多乱而造成数据混乱错误的可能性。这里涉及到线程锁
用锁控制线程间的竞争
这里介绍锁的基本概念以及常见分类,详细在另外的时间再做。
- 共享锁/排它锁
1 | 共享锁和排他锁是从同一时刻是否允许多个线程持有该锁的角度来划分。 |
- 悲观锁/乐观锁
1 | 主要用于数据库数据的操作中,而对于线程锁中较为少见。 |
- 可重入锁/不可重入
1 | 这两个概念是从同一个线程在已经持有锁的前提下能否再次持有锁的角度来区分的。 |
- 公平锁/非公平锁
1 | 这两个概念主要使用线程获取锁的顺序角度来区分的。 |
- 自旋锁/非自旋锁
1 | 这两种概念是从线程等待的处理机制来区分的。 |
详细的参考这里
锁的弊端
不管是何种锁,本质上都是对资源的访问加以限制,让同一时间只有一个线程访问资源。在高并发的时候,锁往往会成为系统的瓶颈,更不用说同时带来的死锁风险。
不用锁解决线程安全的方式
我们接下来讨论有无高效解决线程竞争的模式,避免锁带来的以上问题。
常见线程模型
线程模型的定义
线程模型决定了应用或框架如何执行代码,所以选择正确的线程模型是很重要的事情。通俗的讲,如果同样给你一定数量的线程如(100个),分析实际的业务场景,如何让它们的效率最大化。这就是选取线程模型应该做的事情。
同时线程模型也指线程映射到操作系统进程的模型 https://blog.csdn.net/lyc201219/article/details/79228575
- Future模型
结合Callable接口配合使用,Callable是类似于Runnable的接口。Future是把结果放在将来获取,当前主线程并不急于获取处理结果。允许子线程先进行处理一段时间,处理结束之后就把结果保存下来,当主线程需要使用的时候再向子线程索取。如果不使用Future模型,就需要使用到一个全局变量来保存子线程处理之后的结果。子线程处理结束之后,把结果保存在全局变量中供主线程进行调用。一旦涉及到全局能量便存在着多线程读写全局变量错误的风险。
1 | ExecutorService executorService = Executors.newFixedThreadPool(5); |
- fork&join 模型
该模型包含递归思想和回溯思想,递归用来拆分任务,回溯用合并结果。可以用来处理一些可以进行拆分的大任务。其主要是把一个大任务逐级拆分为多个子任务,然后分别在子线程中执行,当每个子线程执行结束之后逐级回溯,返回结果进行汇总合并,最终得出想要的结果
1 | /** |
- 生产者消费者模型
生产者消费者模型都比较熟悉,其核心是使用一个缓存来保存任务。开启一个/多个线程来生产任务,然后再开启一个/多个来从缓存中取出任务进行处理。这样的好处是任务的生成和处理分隔开,生产者不需要处理任务,只负责向生成任务然后保存到缓存。而消费者只需要从缓存中取出任务进行处理。使用的时候可以根据任务的生成情况和处理情况开启不同的线程来处理。比如,生成的任务速度较快,那么就可以灵活的多开启几个消费者线程进行处理,这样就可以避免任务的处理响应缓慢的问题
- master-worker模型
master-worker模型类似于任务分发策略,开启一个master线程接收任务,然后在master中根据任务的具体情况进行分发给其它worker子线程,然后由子线程处理任务。如需返回结果,则worker处理结束之后把处理结果返回给master
- actor消息模型
actor模型属于一种基于消息传递机制并行任务处理思想,它以消息的形式来进行线程间数据传输,避免了全局变量的使用,进而避免了数据同步错误的隐患。actor在接受到消息之后可以自己进行处理,也可以继续传递(分发)给其它actor进行处理。Actors一大重要特征在于actors之间相互隔离,它们并不互相共享内存。这点区别于上述的对象。也就是说,一个actor能维持一个私有的状态,并且这个状态不可能被另一个actor所改变。
actor并发模型的应用场景?
适合有状态或者称可变状态的业务场景,如果用DDD术语,适合聚合根,具体案例如订单,订单有状态,比如未付款未发货,已经付款未发货,已付款已发货,导致订单状态的变化是事件行为,比如付款行为导致顶大状态切换到”已经付款未发货”。
actor的原理
行为导致状态变化,行为执行是依靠线程,比如用户发出一个付款的请求,服务器后端派出一个线程来执行付款请求,携带付款的金额和银行卡等等信息,当付款请求被成功完成后,线程还要做的事情就是改变订单状态,这时线程访问订单的一个方法比如changeState。如果后台有管理员同时修改这个订单状态,那么实际有两个线程共同访问同一个数据,这时就必须锁,比如我们在changeState方法前加上sychronized这样同步语法。使用同步语法坏处是每次只能一个线程进行处理,如同上厕所,只有一个蹲坑,人多就必须排队,这种情况性能很低。
避免changeState方法被外部两个线程同时占用访问,那么我们自己设计专门的线程守护订单状态,而不是普通方法代码,普通方法代码比较弱势,容易被外部线程hold住,而我们设计的这个对象没有普通方法,只有线程,这样就变成Order的守护线程和外部访问请求线程的通讯问题了。Actor采取的这种类似消息机制的方式,实际在守护线程和外部线程之间有一个队列,俗称信箱,外部线程只要把请求放入,守护线程就读取进行处理。这种异步高效方式是Actor基本原理,以ERlang和Scala语言为主要特征,他们封装得更好,类似将消息队列微观化了。
参考使用Akka Actor和Java 8构建反应式应用
- reactor模型
一图胜千言,来看看Doug Lea大神画的图(Scalable IO in Java)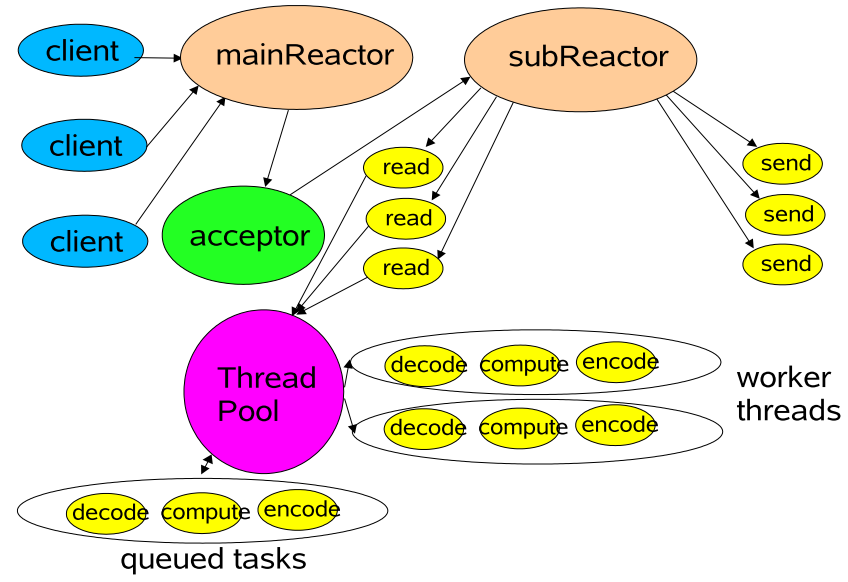
参考资料
- https://www.jianshu.com/p/20b7327f9f56 ThreadPoolExecutor源码分析
- https://blog.csdn.net/wangjinnan16/article/details/78377642 Netty4实战第十五章:选择正确的线程模型
- https://www.cnblogs.com/PerkinsZhu/p/7570775.html 常见线程模型介绍
- http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf Scalable IO in Java

